
In today’s fast-paced world, staying updated with the latest news can be overwhelming. With countless articles published every day, filtering through the noise to find what matters most can feel like an impossible task. This is where AI comes to help. In this blog, we’ll explore how LangGraph helps to build intelligent news summarization . Let’s dive in!
Tools for the Intelligent News Summarization
When it comes to extracting Google search results for specific topics or queries, there are numerous APIs available to choose from.
For this project, we’ll be leveraging NewsAPI to fetch the latest news on a given topic. Its robust functionality and simplicity make it an excellent choice for our project to extract the information. Its free plan is sufficient for our use case.
So sign up and get your NewsAPI key that we’ll use in LangGraph’s workflow.
Steps for News Summarizer
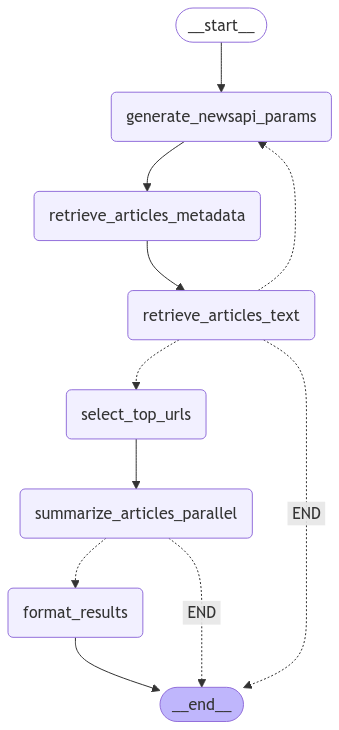
The above are the overall steps for our News Summarizer using LangGraph. Let me break it down and explain the overall process.
- Generate API Parameters Based on User Query Craft the query parameters for the NewsAPI request based on the user’s input (e.g., topic, keywords, date range).
- Fetch Article Metadata Trigger the NewsAPI function to retrieve metadata, including the title, URL, and description of articles related to the query.
- Scrape Article URLs Scrape the URLs obtained in the previous step to extract the full article text. Add these to the list of potential articles.
- Validate the Number of Potential Articles Check if the number of potential articles meets the required number of TLDR articles.
- If less than required, return to Step 1 and fetch more articles.
- Otherwise, proceed to Step 5.
- Filter Relevant Articles Select only the top articles whose content strongly resonates with the user’s query, ensuring high relevance.
- Summarize Article Text If top URLs are available, summarize the text of the selected articles using a text summarization algorithm or tool.
- Format the Summarized Text Organize the summaries into a user-friendly and cohesive format.
- End the Workflow Finalize the process and provide the formatted summaries as the output.
Code walkthrough
Importing libraries
First, let’s import all the necessary libraries for our project.
import os from typing import TypedDict, Annotated, List from langgraph.graph import Graph, END from langchain_openai import ChatOpenAI from pydantic import BaseModel, Field from langchain_core.runnables.graph import MermaidDrawMethod from datetime import datetime import re from newsapi import NewsApiClient import requests from bs4 import BeautifulSoup from IPython.display import display, Image as IPImage from langchain_core.messages import SystemMessage
Declaring state and NewsAPI parameter class
Now, we are going the declare Graph’s State class for the workflow and initial our LLM.
os.environ['OPENAI_API_KEY'] = "YOUR_API_KEY"
#invoke llm
llm= ChatOpenAI()
class GraphState(TypedDict):
news_query: Annotated[str, "Input query to extract news search parameters from."]
num_searches_remaining: Annotated[int, "Number of articles to search for."]
newsapi_params: Annotated[dict, "Structured argument for the News API."]
past_searches: Annotated[List[dict], "List of search params already used."]
articles_metadata: Annotated[list[dict], "Article metadata response from the News API"]
scraped_urls: Annotated[List[str], "List of urls already scraped."]
num_articles_tldr: Annotated[int, "Number of articles to create TL;DR for."]
potential_articles: Annotated[List[dict[str, str, str]], "Article with full text to consider summarizing."]
tldr_articles: Annotated[List[dict[str, str, str]], "Selected article TL;DRs."]
formatted_results: Annotated[str, "Formatted results to display."]
With GraphState, we are also going to declare one another class that will be used to get structured parameters from the LLM that will be passed to the NewsAPI’s function.
class NewsApiParams(BaseModel):
q: str = Field(description="1-3 concise keyword search terms that are not too specific")
sources: str =Field(description="comma-separated list of sources from: 'abc-news,abc-news-au,associated-press,australian-financial-review,axios,bbc-news,bbc-sport,bloomberg,business-insider,cbc-news,cbs-news,cnn,financial-post,fortune'")
from_param: str = Field(description="date in format 'YYYY-MM-DD' Two days ago minimum. Extend up to 30 days on second and subsequent requests.")
to: str = Field(description="date in format 'YYYY-MM-DD' today's date unless specified")
language: str = Field(description="language of articles 'en' unless specified one of ['ar', 'de', 'en', 'es', 'fr', 'he', 'it', 'nl', 'no', 'pt', 'ru', 'se', 'ud', 'zh']")
sort_by: str = Field(description="sort by 'relevancy', 'popularity', or 'publishedAt'")
in the sources parameter of the above NewsApiParams class, I have declared the top new sources from entertainment and general categories.
If you’d like to add more sources tailored to your specific queries, simply visit this link, which provides a comprehensive list of sources across various categories.
Functions for Intelligent News Summarizer
Now, let’s create functions for the overall steps that we discussed above.
def generate_newsapi_params(state:GraphState):
"""This function generates News API params as per user's question."""
#get today's date
today_date= datetime.now().strftime("%Y-%m-%d")
news_query=state['news_query']
num_searches_remaining= state['num_searches_remaining']
past_searches = state["past_searches"]
sys_prompt="""
Today's date is {today_date}
Create a param dict for the News API on the user query:
{query}
These searches have already been made. Loosen the search terms to get more results.
{past_searches}
Including this one, you have {num_searches_remaining} searches remaining. If this is your last search, use all news resources and 30 days search range.
"""
sys_msg= sys_prompt.format(today_date=today_date,query=news_query, past_searches=past_searches,num_searches_remaining=num_searches_remaining)
llm_with_news_structured_output= llm.with_structured_output(NewsApiParams)
result=llm_with_news_structured_output.invoke([SystemMessage(content=sys_msg)])
params={'q':result.q,
"sources": result.sources,
"from_param":result.from_param,
"to":result.to,
"language":result.language,
"sort_by":result.sort_by}
state['newsapi_params']=params
return state
def retrieve_article_metadata(state:GraphState):
"""This gives metadata about the articles"""
newsapi_params= state['newsapi_params']
scraped_urls= state["scraped_urls"]
potential_articles = state['potential_articles']
past_searches= state['past_searches']
#initiate NewsAPI Client
newsapi= NewsApiClient(api_key='YOUR_API_KEY')
#get the articles
articles= newsapi.get_everything(**newsapi_params)
#add the parameters for the history
past_searches.append(newsapi_params)
new_articles = []
for article in articles['articles']:
if article['url'] not in scraped_urls and len(potential_articles) + len(new_articles) < 10:
new_articles.append(article)
state['articles_metadata']= new_articles
def retrieve_article_text(state:GraphState):
"""scrape the websites metadata"""
article_metadata= state['articles_metadata']
potential_articles = []
#header for scraping
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
for article in article_metadata:
url= article['url']
response= requests.get(url, headers=headers)
if response.status_code == 200:
soup= BeautifulSoup(response.content, 'html.parser')
text= soup.get_text(strip=True)
potential_articles.append({"title": article["title"], "url": url, "description": article["description"], "text": text})
state['scraped_urls'].append(url)
state['potential_articles'].extend(potential_articles)
def select_top_urls(state: GraphState) -> GraphState:
"""Based on the article synoses, choose the top-n articles to summarize."""
news_query = state["news_query"]
num_articles_tldr = state["num_articles_tldr"]
# load all processed articles with full text but no summaries
potential_articles = state["potential_articles"]
# format the metadata
formatted_metadata = "\\n".join([f"{article['url']}\\n{article['description']}\\n" for article in potential_articles])
prompt = f"""
Based on the user news query:
{news_query}
Reply with a list of strings of up to {num_articles_tldr} relevant urls.
Don't add any urls that are not relevant or aren't listed specifically.
{formatted_metadata}
"""
result = llm.invoke(prompt).content
# use regex to extract the urls as a list
url_pattern = r'(https?://[^\\s",]+)'
# Find all URLs in the text
urls = re.findall(url_pattern, result)
# add the selected article metadata to the state
tldr_articles = [article for article in potential_articles if article['url'] in urls]
state["tldr_articles"] = tldr_articles
async def summarize_articles_parallel(state: GraphState) -> GraphState:
"""Summarize the articles based on full text."""
tldr_articles = state["tldr_articles"]
prompt = """
Create a * bulleted summarizing tldr for the article:
{text}
Be sure to follow the following format exaxtly with nothing else:
{title}
{url}
* tl;dr bulleted summary
* use bullet points for each sentence
"""
# iterate over the selected articles and collect summaries synchronously
for i in range(len(tldr_articles)):
text = tldr_articles[i]["text"]
title = tldr_articles[i]["title"]
url = tldr_articles[i]["url"]
# invoke the llm synchronously
result = llm.invoke(prompt.format(title=title, url=url, text=text))
tldr_articles[i]["summary"] = result.content
state["tldr_articles"] = tldr_articles
return state
def format_results(state: GraphState) -> GraphState:
"""Format the results for display."""
# load a list of past search queries
q = [newsapi_params["q"] for newsapi_params in state["past_searches"]]
formatted_results = f"Here are the top {len(state['tldr_articles'])} articles based on search terms:\\n{', '.join(q)}\\n\\n"
# load the summarized articles
tldr_articles = state["tldr_articles"]
# format article tl;dr summaries
tldr_articles = "\\n\\n".join([f"{article['summary']}" for article in tldr_articles])
# concatenate summaries to the formatted results
formatted_results += tldr_articles
state["formatted_results"] = formatted_results
return state
def format_results(state: GraphState) -> GraphState:
"""Format the results for display."""
# load a list of past search queries
q = [newsapi_params["q"] for newsapi_params in state["past_searches"]]
formatted_results = f"Here are the top {len(state['tldr_articles'])} articles based on search terms:\\n{', '.join(q)}\\n\\n"
# load the summarized articles
tldr_articles = state["tldr_articles"]
# format article tl;dr summaries
tldr_articles = "\\n\\n".join([f"{article['summary']}" for article in tldr_articles])
# concatenate summaries to the formatted results
formatted_results += tldr_articles
state["formatted_results"] = formatted_results
return state
def articles_text_decision(state: GraphState) -> str:
"""Check results of retrieve_articles_text to determine next step."""
if state["num_searches_remaining"] == 0:
# if no articles with text were found return END
if len(state["potential_articles"]) == 0:
state["formatted_results"] = "No articles with text found."
return "END"
# if some articles were found, move on to selecting the top urls
else:
return "select_top_urls"
else:
# if the number of articles found is less than the number of articles to summarize, continue searching
if len(state["potential_articles"]) < state["num_articles_tldr"]:
return "generate_newsapi_params"
# otherwise move on to selecting the top urls
else:
return "select_top_urls"
Now our functions for the LangGraph workflow are ready. So now let’s build nodes and edges for the graph.
Compile the Graph
workflow = Graph()
#define nodes
workflow.add_node("generate_newsapi_params", generate_newsapi_params)
workflow.add_node("retrieve_articles_metadata", retrieve_article_metadata)
workflow.add_node("retrieve_articles_text", retrieve_article_text)
workflow.add_node("select_top_urls", select_top_urls)
workflow.add_node("summarize_articles_parallel", summarize_articles_parallel)
workflow.add_node("format_results", format_results)
#define edges
workflow.add_edge("generate_newsapi_params", "retrieve_articles_metadata")
workflow.add_edge("retrieve_articles_metadata", "retrieve_articles_text")
workflow.add_conditional_edges(
"retrieve_articles_text",
articles_text_decision,
{
"generate_newsapi_params": "generate_newsapi_params",
"select_top_urls": "select_top_urls",
"END": END
}
)
workflow.add_edge("select_top_urls", "summarize_articles_parallel")
workflow.add_conditional_edges(
"summarize_articles_parallel",
lambda state: "format_results" if len(state["tldr_articles"]) > 0 else "END",
{
"format_results": "format_results",
"END": END
}
)
workflow.add_edge("format_results", END)
app=workflow.compile()
Run the Intelligent News Summarization tool
Now we are all set to test out Intelligent News Summarizer. Let’s run it and check out out how it performs.
async def run_workflow(query: str, num_searches_remaining: int = 3, num_articles_tldr: int = 2):
"""Run the LangGraph workflow and display results."""
initial_state = {
"news_query": query,
"num_searches_remaining": num_searches_remaining,
"newsapi_params": {},
"past_searches": [],
"articles_metadata": [],
"scraped_urls": [],
"num_articles_tldr": num_articles_tldr,
"potential_articles": [],
"tldr_articles": [],
"formatted_results": "No articles with text found."
}
try:
result = await app.ainvoke(initial_state)
return result["formatted_results"]
except Exception as e:
print(f"An error occurred: {str(e)}")
return None
query = "Apple Iphone 16" result=await run_workflow(query, num_articles_tldr=3) print(result)
The output is:
Here are the top 3 articles based on search terms: Apple Iphone 16, Apple Iphone 16, Apple Iphone 16, Apple Iphone 16 * Apple remains banned from selling the iPhone 16 in Indonesia * The ban is due to Apple not meeting local sourcing rules for materials * Despite a $1 billion investment plan to build an AirTag factory in Indonesia * The factory proposal was deemed insufficient to lift the ban * Negotiations between Apple and Indonesia have failed to resolve the issue * Apple's rivals like Samsung have been complying with Indonesia's regulations - Apple plans to expand in generative AI and launch more hardware products in 2025 - The Apple Intelligence software is expected to drive a super cycle in iPhone sales - Competition in mixed reality and potential tariffs in China may affect sales and production - Timing is crucial for Apple's success in 2025 with plans for new home devices and a more affordable iPhone on the horizon * Apple launched new products in 2024, including the Vision Pro and AI-powered iPhone 16 * Faced challenges in China with iPhone sales and antitrust issues in the US and Europe * Introduced Apple Intelligence at WWDC, marking its entry into the GenAI market * Experienced highs and lows throughout the year, including CEO succession questions and criticism about AI competitiveness * Launched the Vision Pro headset, faced an antitrust lawsuit, and rolled out new iPads * Introduced Apple Intelligence at WWDC, promising a "golden upgrade cycle" for iPhones * Launched the first AI-enabled iPhone 16 at the "Glowtime" event * Axed some projects like a subscription service for iPhones and Apple Pay Later, while reassigning talent to Apple Intelligence efforts
Voila! See it gave the summary of the 3 articles very easily. Implement and try this in your own machine and get the AI-powered News summary!
Also Read: Effortlessly Create an Amazing ReAct Agent with LangGraph

