
Artificial intelligence is evolving rapidly, and one of the key challenges in AI development is enabling models to remember and utilize past interactions effectively. Traditional language models process inputs independently, making them incapable of retaining context across conversations. This is where LangMem, a memory management system by LangChain, plays a crucial role. LangMem helps AI models store, retrieve, and reason over historical data, making them more intelligent and responsive.
In this blog, we’ll explore the fundamentals of LangMem, how it works, and how to implement it efficiently in your AI applications.
Why LangMem?
LangMem empowers AI agents to learn and adapt from their interactions over time, enabling more intelligent and responsive behavior. By providing robust tools to extract key information from conversations, it helps optimize agent performance through prompt refinement and ensures the retention of long-term memory.
In addition, LangMem works with any storage system, so you can connect to any desired database to permanently store all the conversations.
Here are some key features of LangMem:
- Core memory API that works with any storage system
- Memory management tools that agents can use to record and search information during active conversations “in the hot path”
- Background memory manager that automatically extracts, consolidates, and updates agent knowledge
- Native integration with LangGraph’s Long-term Memory Store, available by default in all LangGraph Platform deployments
Getting started with LangMem
In this example, we will implement the basic react agent that will have access to the Memory store and will give the answer from it.
First, let’s install the Langmem package.
pip install -U langmem
Now let’s import all the necessary packages and set the OpenAI API key. (you can replace this with your desired LLM )
from langgraph.prebuilt import create_react_agent from langgraph.store.memory import InMemoryStore from langmem import create_manage_memory_tool, create_search_memory_tool import os #set the OpenAI API key os.environ['OPENAI_API_KEY']='sk-XXXXX'
# Import core components
from langgraph.prebuilt import create_react_agent
from langgraph.store.memory import InMemoryStore
from langmem import create_manage_memory_tool, create_search_memory_tool
# Set up storage
store = InMemoryStore(
index={
"dims": 1536,
"embed": "openai:text-embedding-3-small",
}
)
# Create an agent with memory capabilities
agent = create_react_agent(
"gpt-3.5-turbo-0125",
tools=[
create_manage_memory_tool(namespace=("memories",)),
create_search_memory_tool(namespace=("memories",)),
],
store=store,
)
Now let’s test it out!
response=agent.invoke(
{"messages": [{"role": "user", "content": "My name is Kathan and I like Porsche 911"}]}
)
print(response['messages'][-1].content)
##OUTPUT
# Great to meet you, Kathan! I've noted that you like Porsche 911. If there's anything specific you'd like to know or discuss about Porsche 911, feel free to ask!
response = agent.invoke(
{"messages": [{"role": "user", "content": "Tell me about myself with my name."}]}
)
print(response["messages"][-1].content)
##OUTPUT
# Based on the information I have in memory, your name is Kathan, and you like Porsche 911. If you would like to share more about yourself, feel free to do so!
That’s great. As you can see, how effortlessly we’ve created the react agent.
In the hot path vs In the background memory creation
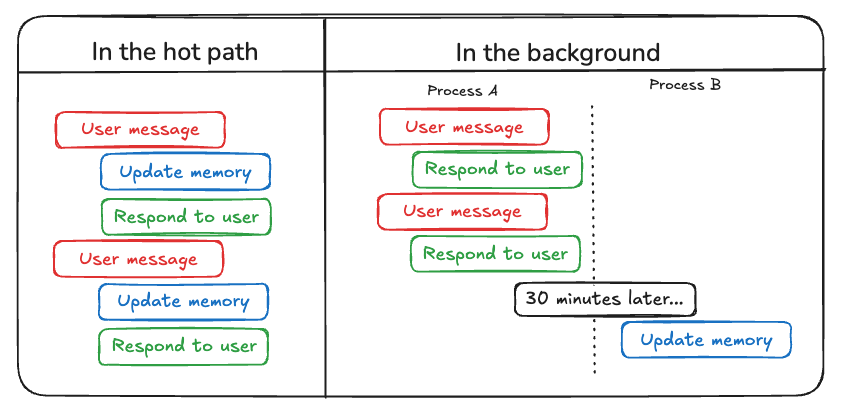
There are two ways to create memory using LangMem.
- In the hot path: Store the conversation in real time
- In the background: Memories are saved subconsciously from the conversation.
In the hot path method
In this method, the conversations are being stored continuously after each conversation. Let’s see it by an example.
from langgraph.checkpoint.memory import MemorySaver
from langgraph.prebuilt import create_react_agent
from langgraph.store.memory import InMemoryStore
from langgraph.utils.config import get_store
from langmem import create_manage_memory_tool
def prompt(state):
"""Prepare the messages for the LLM."""
store = get_store() #
memories = store.search(
("memories",),
query=state["messages"][-1].content,
)
system_msg = f"""You are a helpful assistant.
## Memories
<memories>
{memories}
</memories>
"""
return [{"role": "system", "content": system_msg}, *state["messages"]]
store = InMemoryStore(
index={ # Store extracted memories
"dims": 1536,
"embed": "openai:text-embedding-3-small",
}
)
checkpointer = MemorySaver() # Checkpoint for graph state
agent = create_react_agent(
"gpt-3.5-turbo-0125",
prompt=prompt,
tools=[create_manage_memory_tool(namespace=("memories",))],
store=store,
checkpointer=checkpointer,
)
Here the prompt function helps the search the store and generates the system message that we have used as a prompt in the create_react_agent. Also, we have used a checkpointer.
response=agent.invoke({"messages":[{"role":"user","content":"My favorite car is Porsche 911."}]},
config= config)
print(response['messages'][-1].content)
##OUTPUT
#I've noted that your favorite car is the Porsche 911. If you need me to remember anything else or if you have any other preferences, feel free to let me know!
response=agent.invoke(
{
"messages": [
{"role": "user", "content": "Which is my favorite car?"}
]
},
config=config,
)
print(response['messages'][-1].content)
##OUTPUT
# Your favorite car is the Porsche 911
In the background method
In this method, the memories will be stored in the background without any delay in the flow. Let’s check it out.
from langchain.chat_models import init_chat_model
from langgraph.func import entrypoint
from langgraph.store.memory import InMemoryStore
from langmem import ReflectionExecutor, create_memory_store_manager
store = InMemoryStore( #
index={
"dims": 1536,
"embed": "openai:text-embedding-3-small",
}
)
llm = init_chat_model("gpt-3.5-turbo-0125")
memory_manager = create_memory_store_manager(
"gpt-3.5-turbo-0125",
namespace=("memories",), #
)
@entrypoint(store=store) # Create a LangGraph workflow
async def chat(message: str):
response = llm.invoke(message)
to_process = {"messages": [{"role": "user", "content": message}] + [response]}
await memory_manager.ainvoke(to_process) #
return response.content
# Run conversation as normal
response = await chat.ainvoke(
"I like car. My favorite car is Porsche 911.",
)
print(response)
# Output: That's a great choice! The Porsche 911 is a classic sports car with a powerful engine and sleek design. Its performance and handling make it a top choice for car enthusiasts worldwide. Do you have any specific model or year of the Porsche 911 that you like the most?
Here asynchronous functions store the process in the background.
Conclusion
LangMem revolutionizes AI memory management by enabling models to store, retrieve, and leverage past interactions effectively. Whether using real-time “hot path” storage or background memory consolidation, LangMem ensures that AI agents become more adaptive and context-aware over time. With its integration capabilities across various storage systems and seamless compatibility with LangGraph, it provides a robust foundation for long-term memory in AI applications.
By implementing LangMem, developers can build AI agents that not only remember user interactions but also refine their responses for a more personalized and intelligent user experience. As AI continues to evolve, incorporating memory management solutions like LangMem will be crucial in making AI systems more reliable, consistent, and human-like in their interactions.

