
In classification-related supervised machine learning projects, sometimes we get imbalanced datasets. There are many methods available to deal with that. SMOTEEN is one of the methods that make an imbalanced dataset a balanced dataset. Here you will see Handle imbalanced datasets with SMOTEENN.
Why deal with the imbalanced dataset?
Suppose you have a binary classification problem and in the given dataset you have 1000 rows. Of that 1000 rows, 200 are Yes and 800 rows are No. Then this dataset is called an imbalanced dataset.
There are two ways to deal with imbalanced datasets.
- Upsampling
- Down-sampling
1. Upsampling
In the Upsampling technique, the existing data points corresponding to the outvoted labels are randomly selected and duplicated.
This means that in our example the 200 Yes records will be duplicated until it becomes closely equivalent to 800 No records. After that our imbalanced dataset will become a balanced dataset.
2. Downsampling
Downsampling is a mechanism that reduces the count of training samples falling under the majority class. As it helps to even up the counts of target categories.
So in our example, it will remove the majority class which is 800 No until it becomes equivalent to 200 Yes.
But there is a drawback to using downsampling. Because it removes rows of the majority class. So you can lose some important information about the data. So use Upsampling in most cases.
There are many libraries to do upsampling. One of the popular libraries for upsampling and downsampling is called imblearn.
In oversampling, it uses SMOTE algorithms. SMOTE means Synthetic Minority Over-sampling Technique.
There are many SMOTE algorithms like SMOTE, SMOTENC, SMOTEN, SMOTEENN, SMOTETomek, and many more.
Handle imbalanced datasets with SMOTEENN
Here we will talk about how to do upsampling with SMOTEENN. It combines SMOTE and Edited Nearest Neighbours(ENN). SMOTEEN performs upsampling and downsampling at the same time.
To do upsampling and downsampling with SMOTEENN, first, you have to separate dependent feature and independent features.
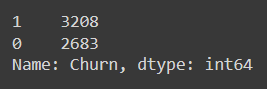
Suppose you have a dataset in which you have to predict whether it is from class 0 or class 1. The number of occurrences of these two classes is given below.

After seeing the above image, you can conclude that this is an imbalanced dataset.
To make a dataset with SMOTEENN first import SMOTEENN from the imblearn library.
Also Read: Feature Selection with Lasso Regression in machine learning
from imblearn.combine import SMOTEENN
sm=SMOTEENN(random_state=101)After you have to call do fit and upsampling of the data. So for that use fit_resample in X and y.
X_res,y_res=sm.fit_resample(X,y)Now if we see X_res and y_res. Then we can see that it became balanced.
And that’s it! Now use this resampled X(X_res) and resampled y(y_res) for model building. And this will give better a result rather than the previous imbalanced dataset.

