
There are mainly two types of problems with machine learning. The first one is regression and the second is a classification problem. After building any model, its evaluation is a very important part of making the best model and optimizing it. There are many evaluation matrices for Classification available for it. Precision, recall, and f1 score are the metrics for classification. Here you will know when to use Precision, Recall, or F1 score to evaluate the classification problem.
What is a confusion matrix?
Before learning when to use these three metrics, you must have to understand the confusion matrix. Because Precision, Recall, and F1 score rely on the confusion matrix. So let’s see what the confusion matrix is. If you know then you can skip this part.

The Confusion matrix can be 2*2 for the 2 prediction classes, 3*3 for the 3 prediction classes, and so on. Here we are dealing with 2 prediction classes therefore we have a 2*2 size matrix.
Metrix contains two parts. Predicted values and actual values with the total number of predictions as you can see above. It has four cases:
True Positive: When the actual value is positive and the model predicted that value is positive.
True Negative: When the actual value is negative and the model predicted that value is negative.
False Positive: When the actual value is negative and the model predicted that value is positive.
False Negative: When the actual value is positive and the model predicted that value is negative.
So as you can see what these 4 cases mean just by looking at their names.
In this matrix, the False positive is called Type 1 Error which is also called False Positive Rate(FPR). And the False Negative is called a Type 2 Error which is also called a False Negative Rate(FNR).
When Recall, Precision, or F1 score is important?
When you have a dataset for a classification task, then it may happen that you have less number of examples for one class and a large number of examples for another class. This type of dataset is called an imbalanced dataset.
If your dataset is an imbalance, then in that condition you may use recall, precision, or f1 score.
Also Read: How to group columns with the mode in DataFrame
What is Recall?
Definition: Out of the total positive actual values how many positives did we predict correctly is called Recall. The formula of it is:

Another name for Recall is Sensitivity.
When to use Recall?
When in the given imbalanced dataset, if your FNR(False Negative Rate) plays a major role then in that case using Recall.
For example, if you are building a cancer detection model to predict whether the person has cancer or not. Then False Negative plays a major role in that.
Suppose the patient has cancer and the model has predicted that the patient has no cancer. In that case, it would be bad for the patient and the model will not be reliable.
So in that type of case use Recall.
What is Precision?
Out of the total positive predicted results, how many positives did we predict correctly is called Precision.
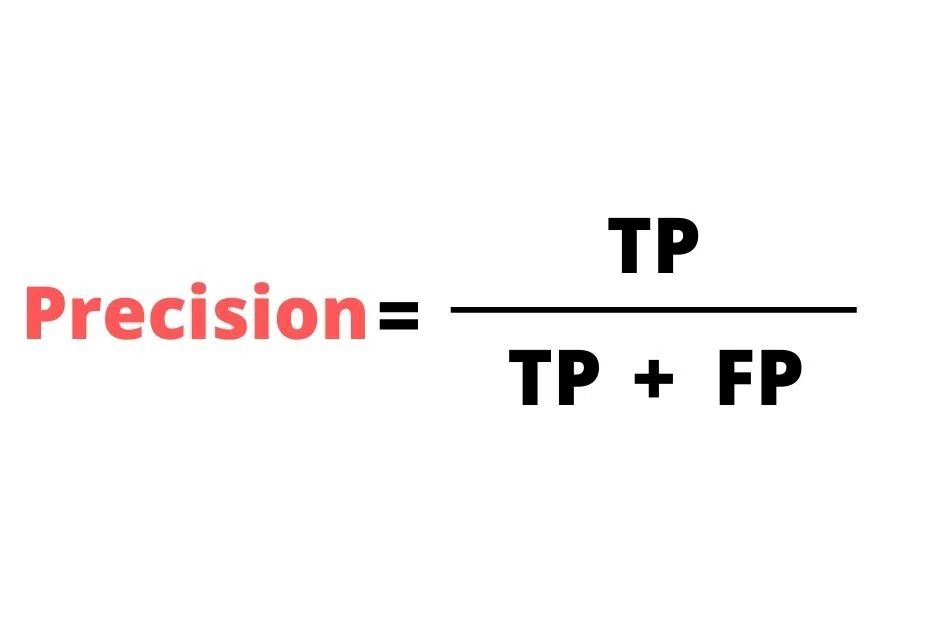
Precision is also called Positive Predicted Value.
When to use Precision?
When in the given imbalanced dataset, if your FPR(False Positive Rate) plays a major role then in that case using Precision.
Suppose you are building Email spam prediction, then FPR is important. Because if the Email is not spam but the model is predicted as spam and if that Email is important to the user, then he will lose that.
So in the cases like this, use Precision.
What is the F1 score?
The formula for the F1 score is :

When to use the F1 score?
As you can see the F1 score is the mixture of both Recall and Precision. When precision and recall are both important in the given imbalanced dataset, then you have to use the F1 score.
If False Positive and False Negative both are important then set β(beta) to 1.
When the False positive is more important than the False Negative then set the β values between 0 to 0.5 based on the problem and your approach.
When the False Negative is more important than the False Positive then set the β values greater than 1.
Also Read: Deploy Flask app using docker and GitHub actions on Heroku

