
To reduce features in a dataset, two methods are there in machine learning: Feature selection and Feature extraction. Recursive feature elimination or in short RFE is the feature selection method. Here is given a complete guide on Recursive Feature Elimination for feature selection in machine learning.
What is RFE?
In Feature extraction, two or more features are combined from existing features and make new features to reduce the number of features.
Feature extraction has methods like Principle Components Analysis (PCA), t-distributed Stochastic Neighbor Embedding (t-SNE), etc.
On the other hand, there is a feature selection method where only important features are selected and the features which contribute less to prediction are discarded.
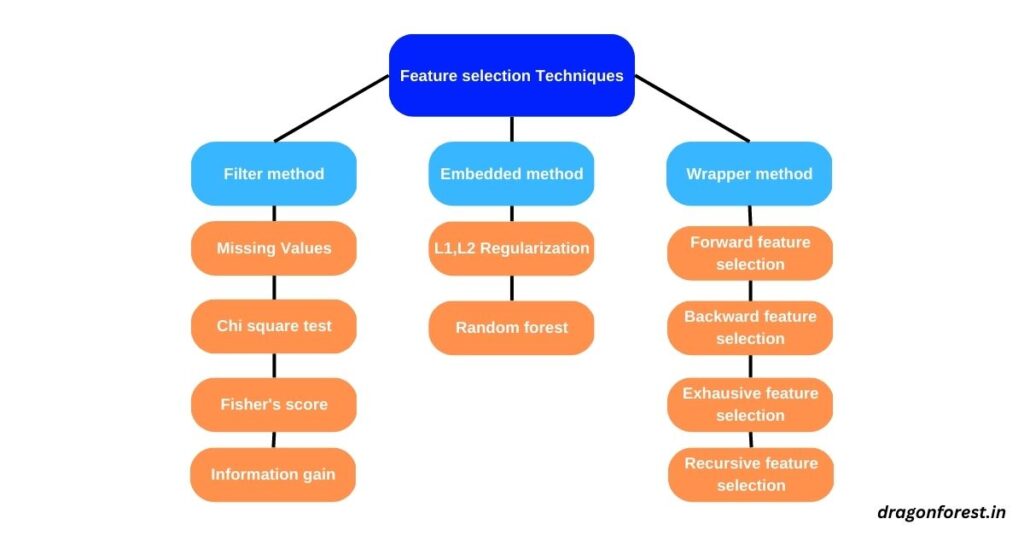
Three methods of feature selection are filter, embedded, and wrapper. In that Embedded and Wrapper method is iterative.
In Filter methods, the features are selected based on statistics.
In the Embedded method, the combination of features is made and evaluated. And the combination with the best performance is selected. Example of this method is Lasso regression, Elastic net, and random forest.
In the wrapper method, the machine learning model is given in the core, in which different combinations are made, evaluated, and compared with other combinations.
So as you can see one of the techniques in the wrapper method is Recursive Feature Elimination. That’s what we are going to discuss.
Recursive Feature Elimination can be used in both regression and classification problems.
Which are the Benefits of using RFE?
If you have features in a dataset, then it could result in a curse of dimensionality. Also, more features take up more space in memory.
That results in slow training of the model and might lead to degradation of the outcome.
So by using Recursive Feature Elimination, you can eliminate these problems.
Which ML algorithm to choose for RFE?
Now as we discussed Recursive Feature Elimination is a wrapper method. So it requires a machine learning model to in core to evaluate the subsets.
There are no restrictions on selecting an ML algorithm. You can choose Logistic regression, a Decision tree classifier for the classification, and Linear regression for regression problems.
But ideally, the tree-based algorithms (i.e. Decision tree) are used for RFE. because they are robust to outliers and correlation.
How to implement RFE in Python?
Though RFE can be made from scratch, it is difficult for beginners. The scikit-learn library provides an implementation of RFE to use. Which is easy.
Implementation of RFE is similar in classification and regression except for the ML model. Here I took the classification dataset but you will be able to use it in the regression dataset without problems.
Let’s implement RFE on the classification problem and see how it can be done.
# test classification dataset from sklearn.datasets import make_classification from sklearn.feature_selection import RFE from sklearn.tree import DecisionTreeClassifier # define dataset X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1)
We have created a dataset that has 1000 rows and 10 columns. Let’s fit Recursive Feature Elimination on it. We are going to select the best 5 features out of 10.
rfe = RFE(estimator=DecisionTreeClassifier(), n_features_to_select=5) _=rfe.fit(X,y)
RFE provides n_features_,n_support_, and n_ranking_ parameters to check which features are selected.
print("Num Features: %s" % (fit.n_features_))
print("Selected Features: %s" % (fit.support_))
print("Feature Ranking: %s" % (fit.ranking_))

Out of 10 features, RFE selected the 3rd,4th,5th,7th, and 9th features.
Also, you can see the ranking of each feature in the 3rd row.
Now let’s filter the columns from X.
X=X[:, rfe.support_] print(X.shape)

Here I have a NumPy array that’s why I directly sliced the array. But you could have the dataset in X, so in that case use X.loc[:, rfe.support_] to filter columns.
How to select the number of features to keep automatically?
The most important hyperparameters in the RFE are the estimator and n_features_to_select. So how many features you keep is crucial.
Luckily sklearn provides RFECV which implements Recursive Feature Elimination with cross-validation and automatically finds the optimal number of features to keep.
Let’s see it in the action.
# test classification dataset from sklearn.datasets import make_classification from sklearn.feature_selection import RFECV from sklearn.tree import DecisionTreeClassifier # define dataset X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, random_state=1) rfecv = RFECV(estimator=DecisionTreeClassifier(),min_features_to_select=3,scoring="accuracy", cv=5)_=rfe.fit(X,y)
RFECV has a min_features_to_select hyperparameter. Which takes how many minimum features you want to keep.
scoring and cv are used to evaluate features.
X=X[:, rfecv.support_] print(X.shape)
Here RFECV suggests 5 columns out of 10.
Final thoughts
RFE is one of the wrapping techniques in feature selection. It takes estimator and n_features_to_select in hyperparameters. The sklearn library also provides the RFECV library which is used to select the important features to keep automatically with cross-validation.

