
Many feature selection techniques include RFE(Recursive feature elimination), VIF(Variance Inflation Factor), VarianceThreshold, and many more. Lasso is one of the feature selection techniques in Data Science, which is used for feature selection for linear regression problems only.
Lasso has two use cases. First, it is used to get rid of the overfitting of the linear regression model. And second, as we will see here is for feature selection.
F.Y.I: Lasso- Least Absolute Shrinkage and Selection Operator
The formula of Lasso:
Here is a formula for the lasso regression:
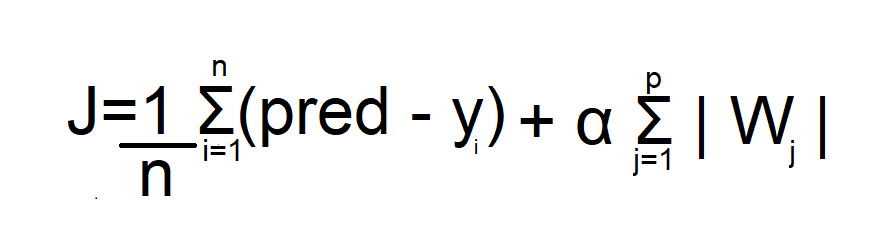
In this formula, the first term is a cost function of linear regression which is the mean squared error. And in the second term is the regularization term of a lasso.
α = Learning rate
W = coefficient of each feature
|W|= mod of W
How Lasso will help in Feature Selection:
The Linear regression formula is Y=WX+B. Where W is called coefficient and b is called intercept. The W can be called slope or coefficient. The W also represents the importance of the feature for the target variable Y. So if you have more than 1 independent feature X, then whoever W value is larger, that feature is contributing most to predicting dependent feature Y.
As you can see in the above formula, the lasso calculates | W |. So the coefficient whose values are very less or close to zero will become zero when the linear model will perform gradient descent. And we can remove that feature whose W value is 0.
So That’s how Lasso can help us to do feature selection on our data.
Also Read: How to sort pandas DataFrame by month names
Performing Feature Selection with Lasso:
First separate training and test data with the train_test_split method.
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=0)Let’s first check the shape of the example data:
print(X.shape)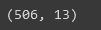
Before applying Lasso regression in your dataset, if your dataset has too much variance then scale it using StandardScaler first. Because you will get a bad result with unscaled data.
from sklearn.preprocessing import StandardScaler
st=StandardScaler()
X_train_std=st.fit_transform(X_train)
X_test_std=st.transform(X_test)now, you are ready to apply Lasso Regression.
Note that the learning parameter of Lasso which is alpha plays a significant role. If you choose a big number then it will make more features’ coefficients zero. And that model will perform poorly.
So you have to choose the very small value of alpha(i.e. 0.001,0.1,0.15) and check how the model is performing on test data. And tune the alpha value according to it.
But Don’t worry like GridSearchCV, Lasso has LassoCV. From this, you can find the best alpha value.
from sklearn.linear_model import LassoCV
ls=LassoCV(cv=5)
ls.fit(X_train_std,y_train)
print(ls.coef_)Output:

Here we got the coefficient(W) of each feature of the dataset. Lasso made 2 coefficients of features zero. This means that these two features are not important in predicting dependent feature Y.
Here you can select a cv parameter according to your dataset. And you can also pass your alpha values with the alphas parameter.
After that check how well the model is performing on the test set with either MSE or with the score() method.
lcv.score(X_train_std,y_train)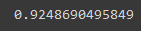
Also Read: What is Stratify in train_test_split? With example
Here my model is performing very well. So now I need to create a mask to replace independent feature X with a selected feature calculated with Lasso regression. And let’s check the new shape of X:
mask=ls.coef_!=0
X=X.loc[:,mask]
X.shape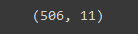
See, the Lasso regression helped for feature selection. That’s how you can apply feature selection with Lasso regression.
If you are facing any issues, let me know in the comment.

