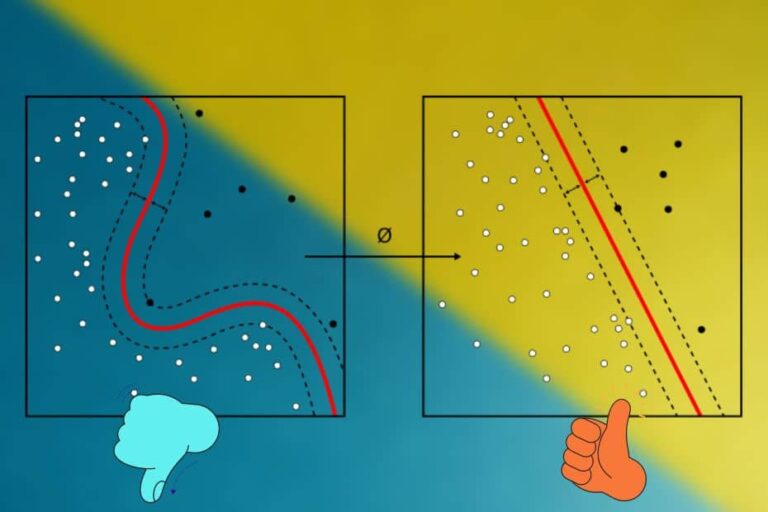
When the model performs excellently on the training dataset but performs very very poorly on the testing or validation dataset that it is called that overfitting. So here you will see the 4 best ways to reduce overfitting in neural networks. Overfitting is one of the problems in machine learning or deep learning. That’s why we cannot rely on the model’s output which is overfitted. But there are some methods available to overcome this situation.
Data Augmentation

So to eliminate overfitting, the easiest solution is to provide more data to the neural network.
With more data, the model will learn more and reduce overfitting in the neural networks.
In the case of image datasets, sometimes it is expensive or nearly impossible to get more images for training. In that case, data augmentation is being performed.
Data augmentation is the process of creating more images artificially if you have access to less number of images for training the neural network. You can increase the size of the data by flipping horizontally, zooming, and scaling the given images.
There are many methods available in TensorFlow to do Data augmentation. Also, there are some ready-made libraries available for data augmentation Augmentor.
Definitely use the augmentation method if you are dealing with small image datasets to reduce overfitting in neural networks.
Regularization
Regularization is the advanced method to eliminate overfitting. Like lasso and Ridge regressions in linear regression, there are two regularizations. L1-regularization and L2-regularization.
L2 Regularization:
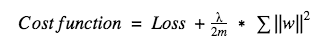
L1 Regularization:
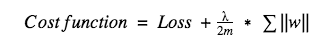
As you can see in the cost function, we have plugged regularization parameters with the traditional Loss function. Here the lambda is a called regularization parameter. And m is the size of training examples. In neural networks, most of the time L2-regularization is used.
And if we talk in terms of the neural networks, then the cost function will look like this for L2-Regularization:
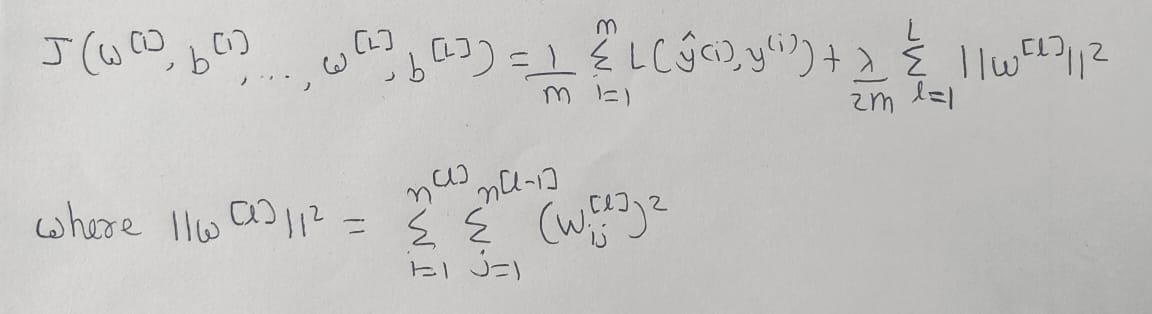
Dropout

Dropout also helps to reduce the overfitting problem. At each layer in the neural network, the different nodes are dropped at random. Dropout ensures that no that nodes are not independent of other nodes.
Dropout is implemented per layer. Therefore you can decide which layers should drop how many nodes at random. Note that the dropout regularization cannot be performed on the output layer because it has only one node.
Sometimes it may produce poor results. In a normal neural network, the layer fixes mistakes that have been done by the previous layer. But in dropout regularization, some layer’s node is dropped randomly so the next node may not fix errors. But in most cases, this performs very well in reducing overfitting.
This method is used widely in computer vision applications. By applying dropout in the convolutional neural network, it makes sure that each node is redundant. So the model can learn better.
Early Stopping
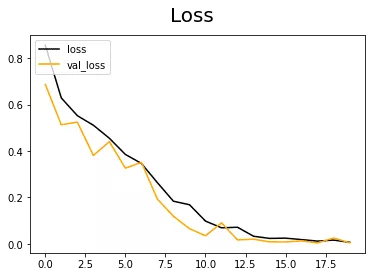
Early stopping is a kind of cross-validation where we keep track of validation errors while training the model.
In this method, training data and validation data are used. The loss function for training data and training data is calculated on each epoch(An epoch means training the neural network with all the training data for one cycle). And when there is no further improvement in the validation set, then the training will be stopped.
There is one method is available on Keras called EarlyStopping. By using that you can perform Early stopping in the model training. You can then visualize how the model reduces training errors and validation errors with a line plot.
So by the Early stopping method too, you can reduce overfitting in neural networks.
So here are the 4 best ways by using them according to your dataset, you can surely reduce overfitting. Hope you will like this!

